





 QQ客服
QQ客服
 微信客服
微信客服


 企业定制
企业定制





安全合规驱动可持续发展
我们以ISO 9001质量管理体系与ISO 27001信息安全管理体系为核心基石,构建全链路合规数据采集框架,严格遵循全球数据安全标准,符合GDPR、CCPA等国际数据法规,为合作伙伴提供合法、可信、可持续的数据服务,助力企业实现安全增长与长期价值

动态代理
动态代理
静态代理
纯净独享ISP,为跨境电商、社媒等业务提供稳定支持
搭配独享高带宽,保障数据传输高效稳定
搭建IPv6静态IP池,满足定制化业务,适配各类IPv6场景
 人工智能数据
人工智能数据
 注:此抓取API现在是网页抓取API
的一部分。所有类型IP仅支持在境外环境下使用。
注:此抓取API现在是网页抓取API
的一部分。所有类型IP仅支持在境外环境下使用。

众多企业及团队信赖
支持大规模采集与校验多模态数据,为企业提供高质量、即用型的 AI 数据基础

搜索视频
获取相关视频、频道和播放列表
每个查询最多700个结果
支持实时与批量处理

下载器
提供高质量的视频与音频格式
结果直接传送到您的云存储
支持全自动批量下载

文字记录和字幕
156 种语言的转录
JSON结构化数据输出
输出与AI兼容

元数据
标题、浏览量、标签及互动指标
输出结构化、AI 可用的数据
支持实时与大规模数据处理
打造 PB 级网络数据采集管道,并针对多模态训练数据进行深度优化
网页抓取API
搜索视频和播放列表
将数据传送至 Amazon S3、GCS、阿里云 OSS 和其他兼容 S3 的存储或通过 API 访问结果
从搜索结果中提取视频ID
通过抓取的结构化数据中,提炼关键元数据、视频ID等
用视频元数据丰富结果
使用获取的视频元数据,完善您的工作流或数据架构

视频下载API
下载视频/音频内容
用YouTube 视频ID的发送请求,我们将负责下载和交付
检索存储
使用获取的视频元数据,完善您的工作流或数据架构
搜索视频与播放列表
支持搜索查询,可将数据源设为 youtube_search 获取标准结果(最多 20 条),或使用 youtube_search_max 获得更全面的结果(最多 700 条)。
可根据需要设置筛选项,并以 JSON 格式输出结构化数据。
查看右侧的输出代码示例,了解具体的响应格式。
{
"results": [
{
"content":[
{
"videoId": "jqSLxWHhI_Y",
"thumbnail": {
"thumbnails": [
{
"url": "https://i.ytimg.com/vi/jqSLxWHhI_Y/hq720.jpg?sqp=-oaymwEcCOgCEMoBSFXyq4qpAw4IARUAAIhCGAFwAcABBg==&rs=AOn4CLAc44Y_w0O3Hz0FD-38sUjzgGAGwg",
"width": 360,
"height": 202
}
]
},
"title": {
"runs": [
{
"text": "Why Adidas Samba lasted 74 years and sold 35,000,000 pairs"
}
]
},
"longBylineText": {
"runs": [
{
"text": "Rose Anvil"
}
]
},
"publishedTimeText": {
"simpleText": "1 year ago"
},
"lengthText": {
"simpleText": "12:59"
},
"viewCountText": {
"simpleText": "677,213 views"
}
}
],
"created_at": "2025-03-05 09:32:43",
"updated_at": "2025-03-05 09:32:44",
"page": 1,
"url": "https://www.youtube.com/results?search_query=adidas&ucbcb=1&sp=EgIQAQ%3D%3D",
"job_id": "7302984396917729281",
"is_render_forced": false,
"status_code": 200
}
],
"job": {
"query": "adidas",
"source": "youtube_search",
"callback_url": "https://ipidea.net:443/api/done",
"id": "7302984396917729281",
"status": "done",
"created_at": "2025-03-05 09:32:43",
"updated_at": "2025-03-05 09:32:44",
"_links": [
{
"rel": "self",
"href": "http://ipidea.net/v1/queries/7302984396917729281",
"method": "GET"
},
{
"rel": "results",
"href": "http://ipidea.net/v1/queries/7302984396917729281/results",
"method": "GET"
}
]
}
}
无需维护的抓取架构
获取 YouTube 视频或音频内容,无需自行搭建抓取流程或配置代理。 我们的下载器专为规模化、易用性与安全性设计,支持面向 AI 的数据传输需求。
无需开发或维护抓取工具和浏览器
自动化处理爬虫机制
将资源专注于数据分析与价值挖掘
只为成功的数据买单。一次API请求,零门槛获取实时数据。
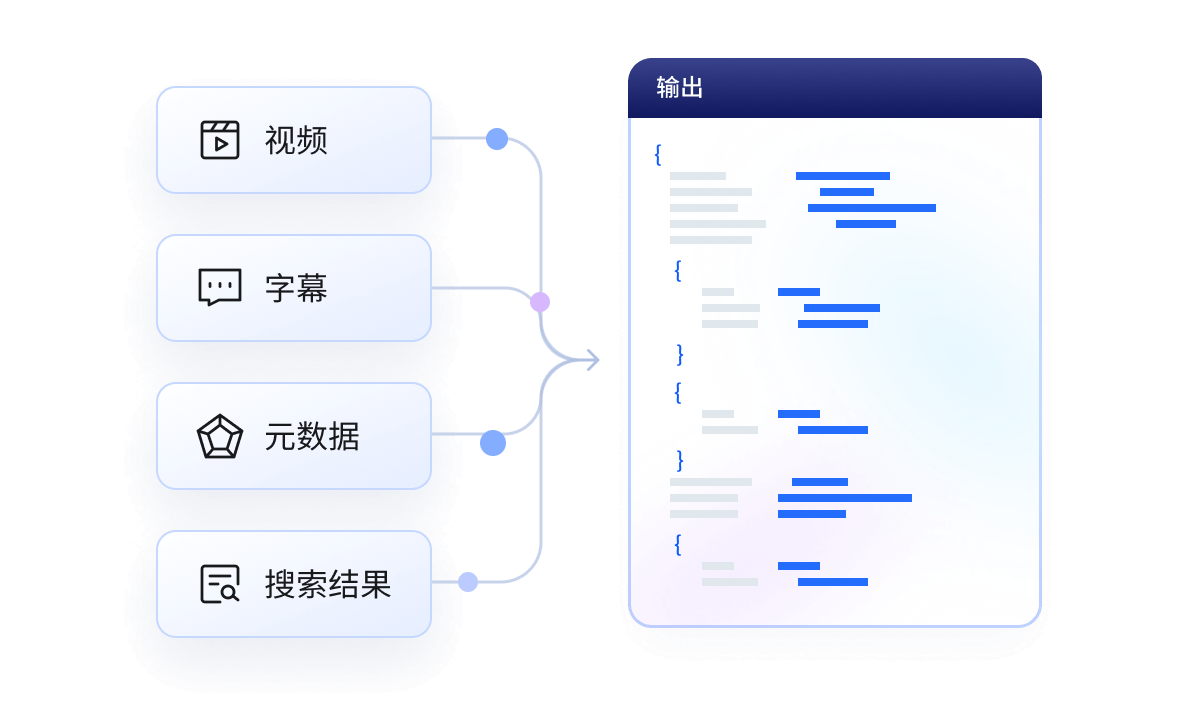
获取可用于 AI 的数据
我们提供可直接用于AI的结构化数据,支持将 YouTube 视频、转录文本、字幕、元数据及搜索结果无缝集成至 LLM、AI 模型与分析流程。
针对人工智能和机器学习进行了优化
无缝 LLM 集成
可扩展且自动化
开箱即用抓取模板,灵活扩展
您定义需求,我们交付数据。
您提出需求目标,我们交付精准数据。我们配备高度可定制的数据抓取程序,内置预设参数,能够帮您节省操作时间,几秒内即可获取所需的 YouTube 数据。
简化您的工作流程,增强自动化,并实现新的效率水平
CrawI4AI
n8n
ChatGPT
CrewAI
AutoGen
Cursor
LlamaIndex
LangChain
LangGraph
Make.com
OpenAI Agents SDK
Zapier
Agno
利用网页抓取API 智能功能进行大规模收集数据


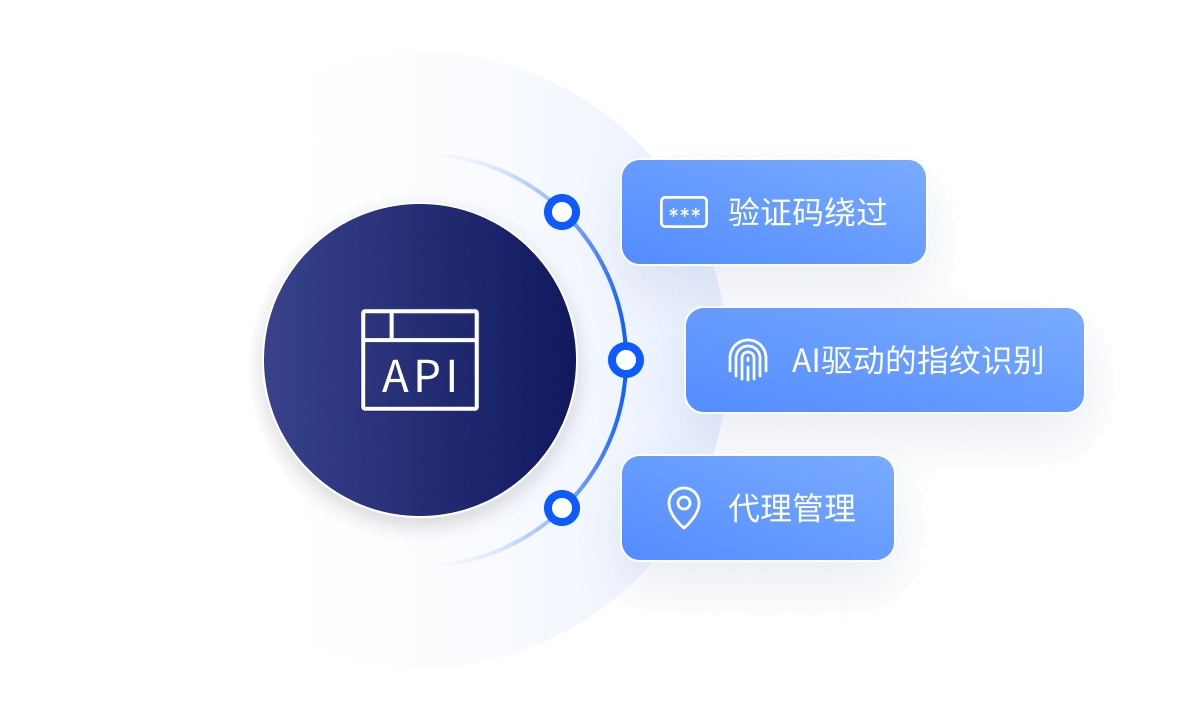
代理管理
使用来自 195 个国家/地区的优质代理池进行 ML 驱动的代理选择和轮换

验证码绕过
自动重试和绕过 CAPTCHA 以实现不间断的数据检索

自定义参数
使用自定义标头和 cookie 增强您的抓取控制,无需额外费用

人工智能指纹识别
独特的 HTTP 标头、JavaScript 和浏览器指纹确保对动态内容的弹性

JavaScript 渲染
从动态和交互式网站中提取准确、高质量的数据

自定义浏览器说明
自动化用户交互(例如点击、输入、滚动等)以加载动态内容并简化抓取工作流程

调度器
以所需频率自动执行重复的抓取作业,并将数据接收到 Amazon S3、GCS、阿里云 OSS 和其他与 S3 兼容的存储

自定义解析器
使用 XPath 或 CSS 选择器定义解析逻辑,以实现结构化数据收集。您还可以使用解析器预设保存并重复使用自定义解析器

安全合规驱动可持续发展
我们以ISO 9001质量管理体系与ISO 27001信息安全管理体系为核心基石,构建全链路合规数据采集框架,严格遵循全球数据安全标准,符合GDPR、CCPA等国际数据法规,为合作伙伴提供合法、可信、可持续的数据服务,助力企业实现安全增长与长期价值

免费试用
 由于政策原因,此服务在中国大陆不可用,不支持访问国内网站
,感谢您的理解!
由于政策原因,此服务在中国大陆不可用,不支持访问国内网站
,感谢您的理解!
© 2025 江苏艾迪信息科技有限公司 苏ICP备20023530号-1 互联网自律公约



