










如何爬取和使用代理IP?
作者:IPIDEA
2022-09-26 15:03:39
尝试过网络爬虫的,可能会遇到过访问虫,这会让我们的爬虫中断无法继续访问网站。这是因为如果一直用同样的ip,访问太多,将被列入黑名单。

然后,我们可以得到ip代理通过动态使用ip代理商防止了允许访问公开数据。今天,让我们学习抓取ip代理的教程。
该爬虫将通过分析免费代理页面获得代理,然后存储到jdb2.每个爬虫程序将通过协程同步获得代理。
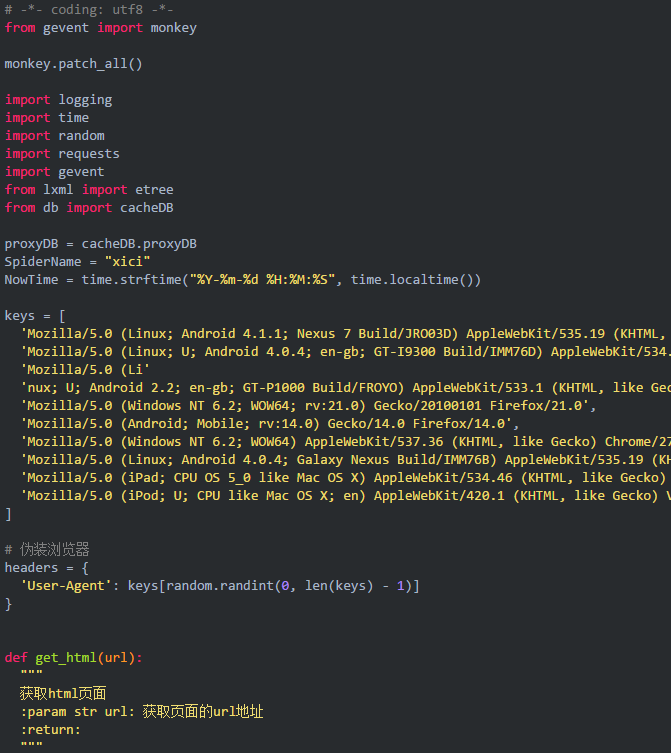
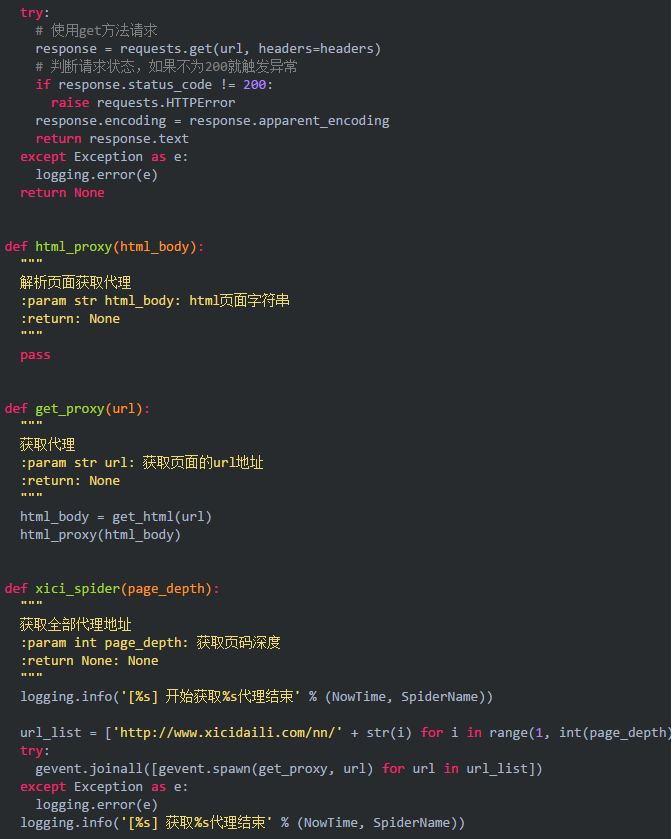
解析页面获取数据,通过观察页面可以发现页面上的数据都是以表格的形式进行排列的,我们使用调试功能查看一下源代码。
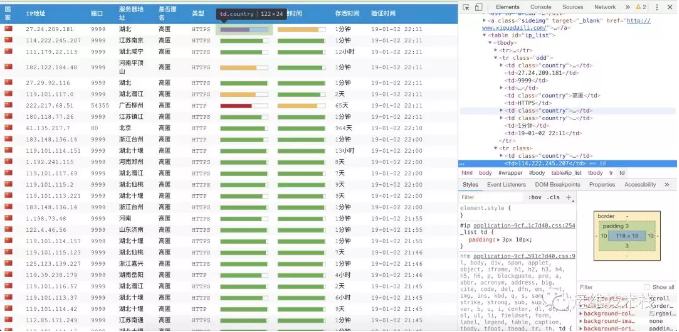
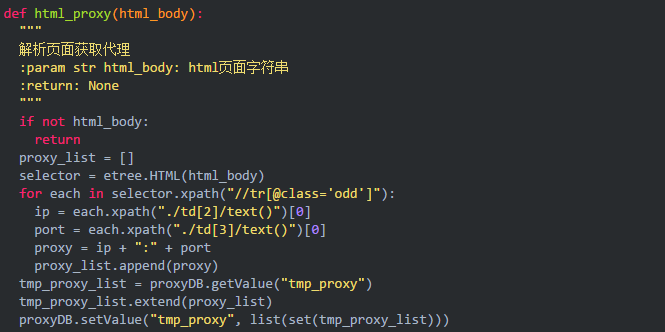
通过观察页面我们可以通过bs4库提供的功能进行页面数据提取,也可以通过xapth进行页面数据提取,以下代码将通过xapth进行页面数据与提取。
使用tornado来定义一个简单的http服务,来提供http api获取数据。
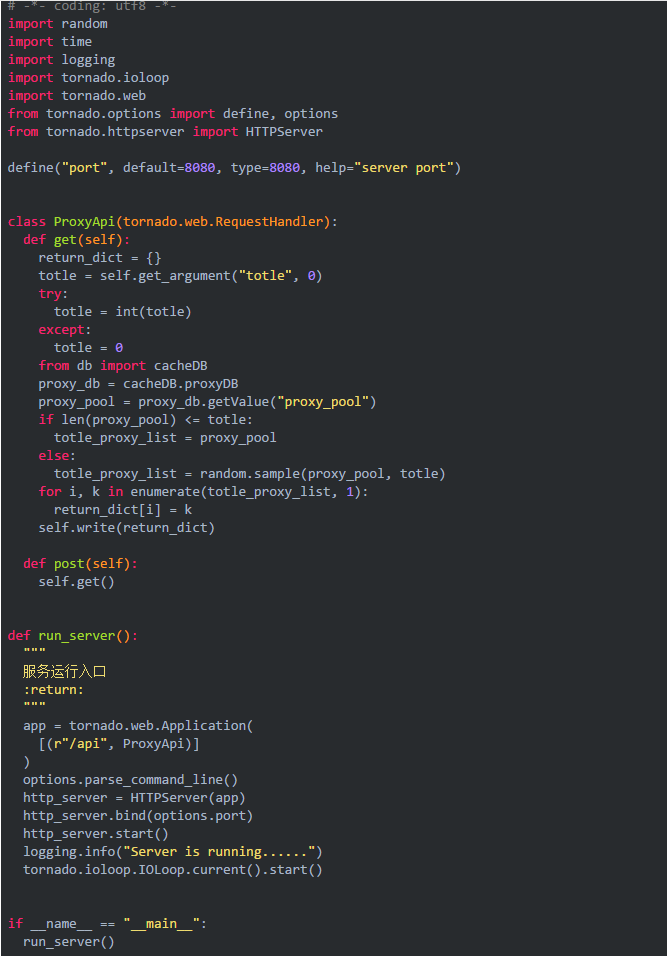
最后通过http://ip:8080/api?totle=10获取指定个数的可用代理(支持get/post方法)。
虽然免费ip不花钱是很爽,但是大家也要尽量少用,因为免费的ip安全确实不大过关,而且连接也不够稳定。
*ipidea提供的服务必须在境外网络环境下使用
热门资讯
微信客服
QQ客服
致电客服
微信公众号

为开发者而生,IPIDEA在不断推动全球企业的数据业务发展。拓展业务,从IPIDEA开始,这是世界500强公司使用的代理网络和数据收集工具。

© 2024 江苏艾迪信息科技有限公司 苏ICP备20023530号-1
