










爬虫通过代理IP防止账号关联获取数据
作者:IPIDEA
2022-10-10 16:23:36
IPIDEA有很多方法可以使用。如果我们需要防止账号关联获取数据,手动收集数据需要很多时间,这也很麻烦,但如果我们通过爬虫获取,就会简单得多。

接下来,我们写一个百度贴吧爬虫界面。
我们需要向这个界面传递三个参数。
main里组合的url地址,以及起始页码和终止页码,表示要爬取页码的范围。
下面IPIDEA以用ip代理爬行贴吧数据为例:先写一个main,提示用户输入要抓取的贴吧名称,并使用urllib.urlencode()转码,然后组合url,假设是lol吧
所以组合之后url就是:tieba.baidu.com/f?
kw=lol
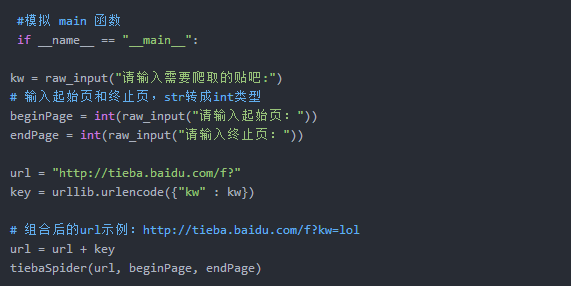
接下来,我们写一个百度贴吧爬虫界面。
我们需要向这个界面传递三个参数。
main里组合的url地址,以及起始页码和终止页码,表示要爬取页码的范围。

在此之前,我们已经编写了一个代码网页。
现在,我们可以把它封装成一个小函数loadPage,供我们使用。
最后,如果我们想在本地磁盘上存储每一页的信息,我们可以简单地写一个存储文件的接口。
事实上,很多网站都是这样的,在类似的网站下html页面编号,分别对应网址后的网页序号,只要找到规则就可以防止账号关联抓取页面。
因此,成为一个爬虫并不特别困难。
如果你仍然没有代码,不知道发生了什么,不重要。
让我们简单地看一下。
以此为模板,我们可以更改一些代码。
通过这种方式,我们可以通过爬虫来简化操作,也可以手动记录而不会太枯燥。
*ipidea提供的服务必须在境外网络环境下使用
热门资讯
微信客服
QQ客服
致电客服
微信公众号

为开发者而生,IPIDEA在不断推动全球企业的数据业务发展。拓展业务,从IPIDEA开始,这是世界500强公司使用的代理网络和数据收集工具。

© 2024 江苏艾迪信息科技有限公司 苏ICP备20023530号-1
